1. Introduction
The recent advancements in micro-electro-mechanical systems (MEMSs) and wireless communication technologies make it possible to build a large scale wireless sensor network (WSN) with a set of hundreds or more sensor nodes [1]. Nowadays, WSNs are used in a wide range of applications, including battlefields and border surveillance, environment and habitat monitoring, industrial process monitoring and control, health-care assistance, home automation, automatic target detection and tracking, etc. [1,2]. Some of the discussed WSN applications requires the remote retrieval of sensor data and are known to be data intensive [2]. Over a decade, the mobile agent computing paradigm has been employed for the remote retrieval of sensor data from a WSN where a set of agents are used to reduce the communication overhead by moving the processing code to the data source, rather than bringing the data to a central processing element (PE) or a sink [3,4]. This approach is a promising data retrieval technique that can be utilized to solve the overwhelming data traffic in WSN by reducing the inherent redundancy of raw data [3,4].
A mobile agent is an autonomous software entity that has the ability to migrate along its itinerary (i.e., migration path) and progressively aggregate the sensor data at each host node [2]. In this paper, we have used a migration path and itinerary synonymously. The aggregated data is then carried by the agent to the next node, where the processing code of the agent starts again and aggregation is performed upon the new data, as well as on the previous data. By dispatching the agents to sensor nodes, a large amount of sensor data may be filtered at each node by eliminating data redundancy [2–4]. The efficiency of a mobile agent-based data aggregation and collection scheme depends upon the agent migration scheme, which affects the overall energy consumption and aggregation cost [5]. The solutions that have been proposed until now, are either using a centralized approach [6–14] or a dynamic and distributed approach [15–18] to determine the migration paths of the agents. In a dynamic and distributed approach, the migration path of an agent is determined using local information at each host, while in a centralized approach, it is pre-computed at the sink node before an agent is dispatched and it is based on the global information of the network topology.
Recently, Mpitziopoulos et al. [2] proposed a clone-based itinerary design (CBID) scheme, which from among all of the proposed centralized approach based migration schemes, this scheme has been proven to be efficient in terms of data aggregation cost and overall response time. In CBID, all the sensor nodes need to transfer their neighbors’ location information to the PE or the sink in order to maintain the global information of the network topology. Since WSN topology changes due to node failures or interference, this enforces a periodic update of global information of network topology. Repeating this process periodically brings a high communication overhead to the sensor nodes. Thus, the energy levels of the sensor nodes may drain quickly. To overcome this problem, we are proposing a dynamic and distributed version of CBID [2], called a clone-based dynamic and distributed agent migration (CDDAM) scheme. Our scheme is where the sensor nodes are organized in the rooted spanning trees, Ti, in a distributed fashion and where multiple agents are dispatched by the PE, one for each root of spanning trees of Ti. When a mobile agent MAj visits a sensor node SNi of tree Ti with two or more children, the agent builds a clone of itself MAclonej,k similar to [2], where k = 1, 2 …m and m is the number of children of the visiting sensor node SNi. MAclonej,k is called the slave agents (SAs) and each SA visits a branch of the tree rooted at SNi. When all mobile agent clones MAclonej,k return to the root node SNi, they handover the collected data to the mobile agent, MAj.
We used three metrics, which are called the average energy consumption, the overall response time, and the success rate of agent’s trip, to evaluate the performance of the CDDAM scheme in comparison with the previous schemes of CBID [2], TBID [14], and MMADIDD [19]. The CBID [2] and TBID [14] schemes are well known centralized approach-based agent migration schemes. However, MMADIDD [19] is a distributed approach-based agent migration scheme. The simulation results show that CDDAM performs better than previous schemes in the presence of faulty nodes within networks, and manages to report aggregated data to the sink faster.
The rest of this paper is organized as follows: in Section 2, we briefly describe other related work. In Section 3, we present the system model and list the assumptions contained in our work. In Section 4, we describe the CDDAM protocol in detail. In Section 5, we describe simulation scenarios and discuss the performance analysis of the protocols with respect to the selected metrics of interest. Finally, we conclude this paper in Section 6.
2. Related Work
Over the last decade, the agent-based data aggregation schemes have been proposed for energy efficient and scalable data collection operations in WSNs, where a mobile agent visits a set of nodes and progressively aggregates the data and returns back to the sink with the aggregated results. The efficiency of agent-based data aggregation depends on its migration protocols. In this section, we present a review study on the existing agent migration schemes that can be classified as a centralized or distributed approach-based scheme, as shown in Fig. 1. This classification is based on the place where agents’ migration decisions are made. Table 1 shows the comparison of agent migration protocols that have been proposed up until now.
2.1 Centralized Approach-Based Schemes
In centralized approach-based schemes, the sink or PE collects the global information of network topology and computes the optimal migration path of the agents before dispatching them for data aggregation. In [6,7], the authors proposed a mobile agent-based distributed sensor (MADSA) network for energy efficient and scalable data aggregation. In [6], performance improvement of MADSA over the client/server model is shown using both analytically and through simulations. In [7], the authors proposed two simple heuristic algorithms, local closest first (LCF) and global closest first (GCF), to determine the itinerary for an agent migration. These heuristic algorithms are centralized and are not scalable since they are based on the global information of the network topology.
Wu et al. [8] proposed a genetic algorithm-based solution for planning the itinerary of an agent. This algorithm provides superior performance than the LCF and GCF algorithms do. However, the algorithms proposed in both [7] and [8] employ a single agent for data aggregation and collection tasks. The performance of a single agent-based approach declines as the network size increases. This is due to an increase in the agent’s state size as it traverses more sensor nodes, which results in more energy consumption and round trip delays. The algorithms proposed in [7,8] assume a perfect data aggregation model, which is a non-realistic assumption.
Mpitziopoulos et al. [9] have proposed a near-optimal itinerary design (NOID) algorithm where the Esau-Williams heuristic is used for finding an appropriate number of mobile agents and their near-optimal itineraries. In NOID, the parallel deployment of multiple agents is suggested where each agent visits a subset of nodes. NOID outperforms the single agent-based approaches (e.g., LCF, GCF, and GA), in terms of data fusion cost and overall response time [9], but it endures high computational complexity in determining the agents’ itineraries.
In [10–13], the authors proposed multi-agent itinerary planning (MIP) algorithms that help in the collection of concurrent sensor data to reduce latency. These algorithms differ in source node grouping methods. In [12], the authors used an angle gap for grouping all the source nodes in a particular direction as a single group. This approach does not describe how to find out an optimal angle gap threshold. In [13], the authors proposed a genetic algorithm by encoding how many agents are dispatched and which sensor nodes are visited by individual agents. The limitation of a genetic algorithm-based approach is its higher computational complexity [20]. These algorithms assume that the set of source nodes to be visited by the agents are predetermined, which limits the application scope of the network.
Mpitziopoulos et al. [2] proposed a CBID algorithm where agents are dispatched in parallel that sequentially visit nodes arranged in tree structures and after visiting a node with two or more child nodes, the master agent makes clones of themselves. Each slave agent visits a sub-branch of the tree. When all slave agents return back to their parent node, they hand over their collected data to the master agent [2]. In CBID [2], agent’s packet needs to carry extra cloning information about where to make clone. This algorithm has limited scalability.
In [14], the authors proposed a greedy tree-based itinerary design (TBID) algorithm to find near optimal itineraries for multiple agents. This algorithm is executed centrally at the sink and statically determines the number of agents that should be employed and their itineraries. The main theme of the TBID algorithm is to divide the area around the sink into concentric zones to construct the near optimal itinerary tree from inner zones to the outer zones. They used post order traversal with a possible shortcutting of the itinerary tree to derive an itinerary for each agent.
The main limitation of a centralized approach-based agent migration scheme is that it uses static migration paths (i.e., itineraries), which is based on a stale view of the network topology. This approach lacks dynamic recovery from node or communication link failures.
2.2 Distributed Approach-Based Schemes
The distributed approach-based agent migration protocol helps the agent to change the route dynamically according to the current state of the network.
Xu and Qi [15,16] proposed a dynamic agent migration algorithm for a target tracking application. In this method, an agent migrates to a sensor node that can get more accurate information about the target location by consuming less energy. For selecting the next node, they defined a cost function, which includes the following three components: energy consumption, information gain, and the remaining energy of a node. Once an agent accumulates sufficient information so that the accuracy of the estimation meets the desired level, the agent will terminate the migration and return to the sink [15,16]. This algorithm is more time expensive and may face difficulty in returning back to the sink without additional forwarding information.
In [17], the authors proposed the mobile agent-based directed diffusion (MADD) where an agent visits a subset of nodes. In MADD, the sink uses the first phase of the directed diffusion algorithm [21] to determine the subset of nodes. However, the actual data aggregation is carried out by dispatching an agent that sequentially visits the subset of nodes [20]. Shakshuki et al. [18] proposed a software agent-based directed diffusion where the order of node visits is determined at the sink node, but the authors did not describe the procedure. This method takes the routing cost and the remaining energy of a node for selecting a next node to be visited by an agent. The main limitations of the schemes described in [17,18] are that they depend on a directed diffusion scheme, that they incur extra communication overhead for agent migration, and that they are only applicable for query based data gathering applications.
Gupta et al. [19] proposed a multiple mobile agents with dynamic itineraries-based data dissemination (MMADIDD) protocol where nodes are organized in a set of the wedge regions and each agent is responsible for gathering aggregated data from each wedge region. The route of an agent is dynamically decided at each hop using cost function. MMADIDD adapts to unexpected node failures during an agent migration, but consumes slightly more energy than TBID [14]. This protocol provides a fair amount of fault tolerance, but the migration of agents depends on the wedge structure.
The work described in this paper also uses a distributed approach where nodes are organized in a set of spanning trees using a distributed algorithm. In the case of node failures, each orphaned node invokes a local recovery mechanism to find the new parent node, in order to maintain the tree topology. For agent migration, our protocol uses a dynamic and distributed approach where the migration of agents is decided at each visited sensor node.
3. System Model and Assumptions
We consider a sensor network that is composed of a set of sensor nodes and a processing element, called a sink node, which is placed at the center of the monitoring region. Each node is equipped with an omni-directional antenna. The sensor nodes, including the sink node in the network, have an equal communication range, such as rmax. The sink node has enough battery power and computational capability to handle all of the necessary calculations, while the sensor nodes in the network have limited battery power and computational capability. For our proposed scheme we used a network model similar to the model used in [2,14], and is shown in Fig. 2.
4. Proposed Protocol
In this section, we present a clone-based dynamic and distributed agent migration (CDDAM) scheme for periodic data aggregation and collection in WSNs. The operation of CDDAM consists of two phases: (1) the rooted spanning tree construction and (2) the clone- based agent migration phase. This section describes each phase in detail. The data structures used in processing are listed in Table 2.
4.1 Rooted Spanning Tree Construction
In this phase, the sink node creates an RSTreeCreationPkt packet, which contains the following three fields: senderNodeID, levelNo, and parentID. The field senderNodeID is the node ID of the sender node of this packet, levelNo is the number of hops to the root of the spanning tree, and parentID is the node ID of the sender’s parent. The field levelNo and parentID is set to 0 by the sink node. The value of levelNo of any node indicates the level number of the node in the tree. After the creation of the RSTreeCreationPkt packet, the sink broadcasts it. Any node that is within the transmission range of the sink receives the RSTreeCreationPkt packet and then becomes the children of the sink node. Each of these nodes then broadcast an RSTreeCreationPkt packet, which advertises that they are at level one. The sink node hears these broadcasts and sets the senders as its children. All the nodes of level one become the root of their spanning tree. Nodes that have not joined the spanning tree yet, make the sender their parent after receiving these packets. If a node receives more than one packet, it selects the parent node whose packet was received with the highest received signal strength indicator (rssi) value. Equation 1 expresses this condition.
Here, SNj,k is sensor node j at level k of tree Ti and Parent(SNj,k) is the parent node of the sensor node SNj,k, SNx,l is node x at level l, and l and k are the level numbers of the sensor node. This process is repeated until all of the nodes have joined the spanning tree.
Each node maintains a CandidatesForParent table having the three fields of nodeID, levelNo, and rssi. This table keeps the information of only those neighbors whose levelNo is less than or equal to its own levelNo. The rssi is the received signal strength indicator of the received RSTreeCreationPkt packet. This table is used to deal with the node failures. At the end of the tree formation phase, each node knows its parent node, its children, and its level number. Each node waits for time, tdelay before broadcasting its RSTreeCreationPkt packet. The value of tdelay depends on slot time assignment, tst of MAC protocol. The value of tdelay is calculated as tdelay= m* tst. Here, m is the maximum number of possible parent nodes in its transmission range. The pseudo-code for the rooted spanning tree construction phase is given in Algorithm 1.

After the construction of the rooted spanning trees, each node disseminates the depth of its sub-tree back towards the root of the tree. Leaf nodes initiate this by disseminating a depth of 1 to their parent. When a node has received a packet from each of its children reporting its depth, it decides on the maximum depth of its children and adds one for itself and sends its depth to its parent. Once the internal sensor node SNj of tree Ti has received the depth of the sub-tree rooted at SNj, it sets up the maximum expected waiting time (twait) taken by a slave agent to complete its migration within the sub-tree Tisubtree, k
4.2 Clone-Based Agent Migration Phase
In this phase, the sink node creates mobile agents, MAj for each rooted spanning tree, Ti. After that, the sink node dispatches an agent to each root of Ti for data aggregation and collection tasks. An agent starts data aggregation and collection from the leaf node of the Ti.
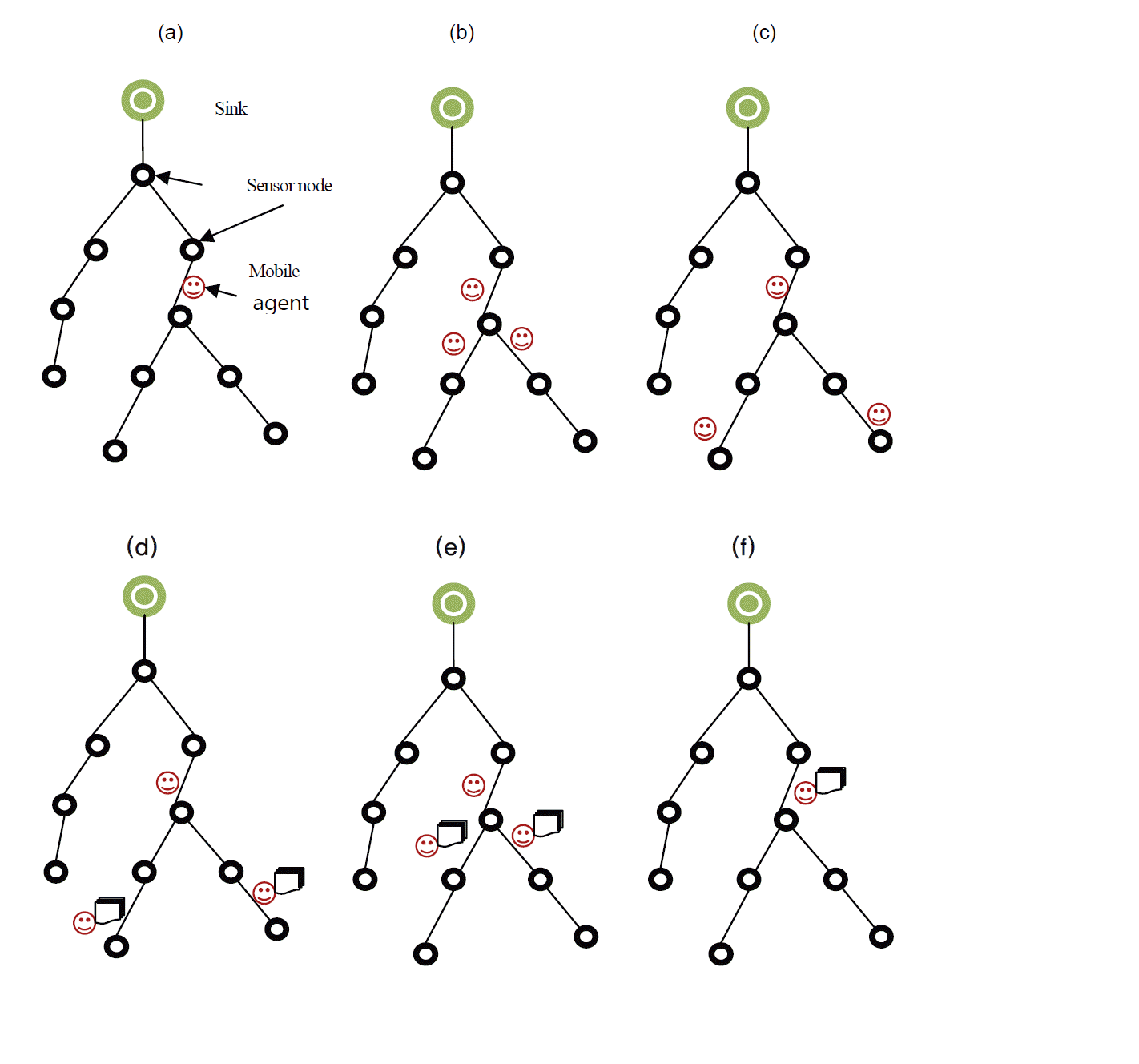
Each MAj starts its migration from the root node of spanning tree Ti. When it reaches a sensor node SNi with two or more child nodes, it builds clones of itself MAclonej,k similar to [2], where k = 1, 2, ..m and m is number of children of the visiting node SNi. Each clone agent MAclone j,k is dispatched to visit the child node of the tree branch. However MAj remains on the parent node SNi. When slave agent MAclone j,k reaches a leaf node, it starts performing the data aggregation task and returns back to the parent node SNi where all of the data collected by MAclone j,k is handed over to MAj. After that the MAclone j,k destroy it selves.
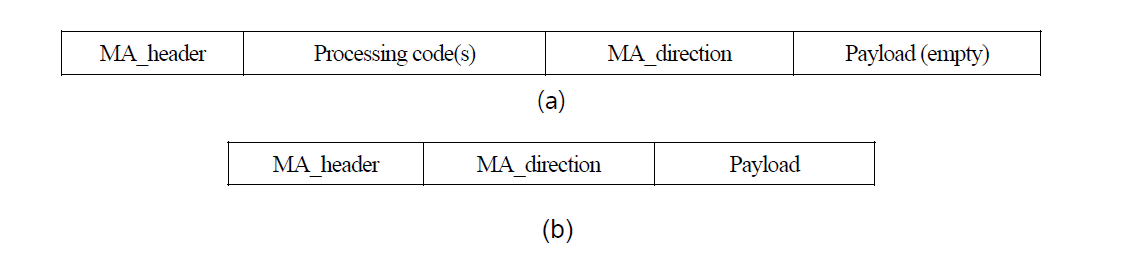
The structure of mobile agent packet is shown in Fig. 3. An agent packet contains the following four fields: MA_header, Processing code, MA_direction, and Payload. Initially, the MA_direction is set to DOWN, which indicates the moving direction of an agent from the root to the leaf node of the spanning tree Ti. When an agent reaches the leaf node, it sets the MA_direction to UP and starts data aggregation from the leaf node towards the root node. During MA migration from the root to the leaf node, the processing code part of the agent packet is stored at each node. Therefore, there is no need to carry the processing code parts of an agent when an agent moves in the UP direction.
Algorithm 2 gives the details of the agent migration process within each tree Ti. Each MAj waits for its clone agent MA clone j,k up to twait maximum time, which can be computed by Eq. (2).
Here, depthTi is depth of sub-tree Ti, ttrans is one hop transmission delay, and tproc is the time needed for the agent to complete its data aggregation at each node. Fig. 4 illustrates the agent migration in a tree, Ti.
4.3 Dealing with Node Failures
The sensor nodes are a resource-constrained device, which make them highly prone to sudden failures. The most common reason for node failure is due to energy depletion. Therefore, in the proposed scheme, whenever the residual energy of a node SNi goes down below a threshold energy level Ethreshold, SNi broadcasts a beacon packet to inform its neighbors that it cannot be a part of the spanning tree Ti. After receiving this beacon packet from node SNi, each node deletes the entry of the dying node from its CandidatesForParent table. When a node fails, its children become orphan nodes. For dealing with this case, each orphaned child (u) finds another sensor node (v) in its CandidatesForParent table with the maximum RSSI and u.levelNo > v.levelNo that should be connected to the spanning tree to act as a parent node. If u failed to find any parent node with above condition, it looks for a node v with maximum RSSI and u.levelNo = v.levelNo. But in case of later, there is some possibility that siblings may become parent of each other which may cause a loop. After finding the suitable parent node, each orphaned node u sends an AttachMe packet to its new parent v. The AttachMe packet contains the following three fields: the orphaned node ID (orphaned_nodeID), the node ID of the new parent v (newParentID), and the depth of its sub-tree (depth_of_tree). After receiving the AttachMe packet from the orphaned node u, the parent node v sends acknowledgement to u and adds node u in its list of children. If the new parent node v finds any changes in its depth, it sends new depth to its parent and this process continues up to the root node of the spanning tree Ti.

5. Performance Analysis
This section presents the simulation results of our proposed protocol, CDDAM, and provides its comparison to CBID [2], TBID [15], and MMADIDD [19]. The analysis of the results is also provided here.
5.1 Simulation Environment
We have simulated and tested the proposed protocol using the Castalia simulator, v.3.2 [22]. The sensor nodes were randomly deployed over a square-monitoring field with a fixed node density (0.0052 nodes/m2). The number of nodes was varied from 25 to 200 nodes to show the scalability property of the protocols. All of the sensor nodes had the same transmission range and battery power. For analyzing the results, each network scenario was executed 10 times and the results were plotted using a confidence interval of 95%. The simulation parameters used in our experiments are shown in Table 3.
We have used the following metrics to evaluate the performance of the protocols:
-
Average energy consumption (Eavg): this is measured as the amount of energy consumed by a node, due to communication, computation, and sensing in each round of data aggregation and collection. Eavg is calculated using Eq. (3).
-
Overall response time (Toverallresponsetime): this is measured as the time taken to complete one round of data aggregation and collection tasks. Toverallresponsetime is calculated using Eq. (4).
Here, Ti,j is time taken by the jth agent of the ith round to complete its data aggregation task and n is the number of rounds. -
Success rate of agent’s round trip (Srate): this is measured as the percentage of agents that were received by the sink over the total number of agents dispatched.
Here, NreceivedAg ents is the number of agents successfully received at the sink after completing their round trip and is the total number of agents dispatched by the sink in the network.
5.2 Impact of the Network Size
Fig. 5(a) and (b) shows the performance comparison of CDDAM with CBID, TBID, and MMADIDD, in terms of the average energy consumption with the varying number of nodes for different accumulated data, d (i.e. for d=100 and d=200, respectively). It demonstrates that average energy consumption increases as the number of node increases. This occurs due to the increase in the length of an agent’s itinerary and the number of nodes visited by an agent. The CDDAM protocol takes approximately 8% less energy than CBID, as shown in Fig. 5(a). This is due to the use of a shorter agent packet in the CDDAM protocol, which results in lower energy consumption than CBID. However, CBID is a centralized approach-based protocol where an agent needs to carry a pre-computed itinerary list, as well as cloning information, which increases the size of the agent packet. This results in extra transmission energy consumption for the agent migration within the network. Moreover, we observed that CDDAM consumes approximately 14% less energy than TBID. This is because CDDAM dynamically computes the routes of an agent at each host and uses the agent-cloning concept. Also, the agent’s itinerary length is shorter than TBID and MMADIDD. Due to the use of the cloning concept, each clone agent (SA) needs to carry a lighter payload. Furthermore, CDDAM consumes approximately 16% less energy than MMADIDD. This is because MMADIDD does not use the agent-cloning concept and agent’s itinerary length is longer, as compared to CDDAM.
Fig. 6(a) and (b) shows the performance comparison of CDDAM with CBID, TBID, and MMADIDD in terms of the overall response time for d=100 and d=200, respectively. It demonstrates that the overall response time increases as the number of nodes increases. This is due to the increase in the number of nodes visited by an agent. The overall response time of CDDAM is approximately 2% less than CBID. This is because an agent does not need to carry a pre-computed itinerary list and cloning information in the CDDAM protocol. However, CDDAM takes approximately 36% less time than TBID to complete one round of data aggregation and collection tasks. Moreover, the overall response time of MMADIDD is approximately 38% more than CDDAM. This is because CDDAM uses the agent-cloning concept, which offers a parallel deployment of the clone agent to complete the task, which results in a better response time than other schemes.
5.3 Impact of Faulty Nodes
Fig. 7 shows the performance comparison of CDDAM with CBID, TBID, and MMADIDD in terms of the success rate of the agents’ trip in the presence of faulty nodes. It can be observed from Fig. 6 that CDDAM and MMADIDD perform better than the protocols for other schemes in the presence of faulty nodes. This is because CDDAM and MMADIDD protocols are distributed algorithm based protocols where next the hop to be visited by an agent is dynamically decided at each host. However, CBID and TBID protocols are centralized algorithm based protocols where agents follow pre-computed routes for the migration of agents, which reduces the success rate in the presence of faulty nodes.
6. Conclusion
This paper presents a dynamic and distributed algorithm-based agent migration scheme, CDDAM for data aggregation in WSN. This scheme creates a virtual infrastructure, called rooted spanning trees, Ti, to perform the migration of agents within the network. CDDAM is a distributed version of the existing centralized-approach based migration scheme of CBID [2]. CDDAM not only provides a fault tolerance, but also significantly improves the performance when compared to CBID in terms of the average energy consumption, overall response time, and success rate of the agents’ trips. The local information of the node is used to deal with the faulty nodes in this scheme. We have also studied the behavior of the proposed scheme through extensive simulation experiments and compared the performance with the three well-known schemes of CBID, TBID, and MMADIDD. The simulation results demonstrate that CDDAM has superior performance than the other schemes in the presence of faulty nodes. In our future work, we plan to incorporate security features in CDDAM to thwart the agents’ migration to malicious host nodes.