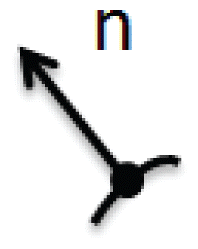1. Introduction
As the number of images increase exponentially, the needs for extracting meaningful information from these images also escalates. Although numerous approaches on text detection have been published, it is still challenging to localize text in natural scene images. This has caused researchers to be interested in many aspects of the problem.
Text detection methods can be divided into the two main categories of texture-based and region-based. A complete survey of text detection with related applications can be found in [1]. Texture-based approaches usually require a high computation time. Five localized features are proposed in [2] with a neural network classifier to locate the regions of text in an image, in which the result is invariant to scale and the 3D orientation of the text. It also allows for the recovery of text in cluttered scenes. The frequency domain was also considered using the Fourier transform [3], discrete cosine transform (DCT) [4], and wavelets [5]. Frequency domain methods are based on the fact that small texts produce strong texture responses, and therefore, are only effective for scenes with small character strokes.
The region-based approach is widely used because it is simple in its algorithm and robust against illumination changes. Region-based approaches determine spatial correlation based on edge features [6] or connected component features [7] of text strokes. In edge-based methods, the edges of the text boundary are identified and merged, and then several heuristics are used to filter out the non-text regions or outliers. On the other hand, the connected component based methods use a bottom-up approach by grouping small components into larger components until all of the regions are identified. In region-based methods, however, many non-text regions are misclassified as text regions because the information in neighboring regions is not considered.
These approaches, especially in the region-based method, generate a high false positive rate and require many parameter settings in heuristics depending on the specific application.
In contrast, Nguyen et al. [8] first used tensor voting for detecting text from images. By adopting tensor voting, the use of heuristic rules was minimized. Nevertheless, since tensor voting deals with points, or more specifically the pixel level, this method did not take into account a region’s properties (such as area, orientation, aspect ratio, etc.) when candidate text regions were selected. As a result, a large amount of false positives, or commonly known as a ‘false alarm,’ were extracted. This leads to low precision in a lot of cases, which are shown in Fig. 1. Moreover, as the only input for the tensor voting process, the centroids obtained from connected components of an edge map could not cover all of the sections that are text regions in the image. Consequently, several texts were left behind undetected, as shown in Fig. 2. Since the publication of this original paper, there has been limited progress in this direction.
Inspired by the observation that there is usually a large amount of corner points and center points of edge components close together in text characters, we are proposing a novel combination of corner point detection, edge detection, tensor voting, and a few rules to locate text in natural images. The experiments show that these changes did improve previous development in various cases.
The remainder of this paper is organized as follows: in Section 2, we present the proposed method. The experiment results are given in Section 3. Finally, Section 4 provides our conclusions and future work.
2. Proposed Approach
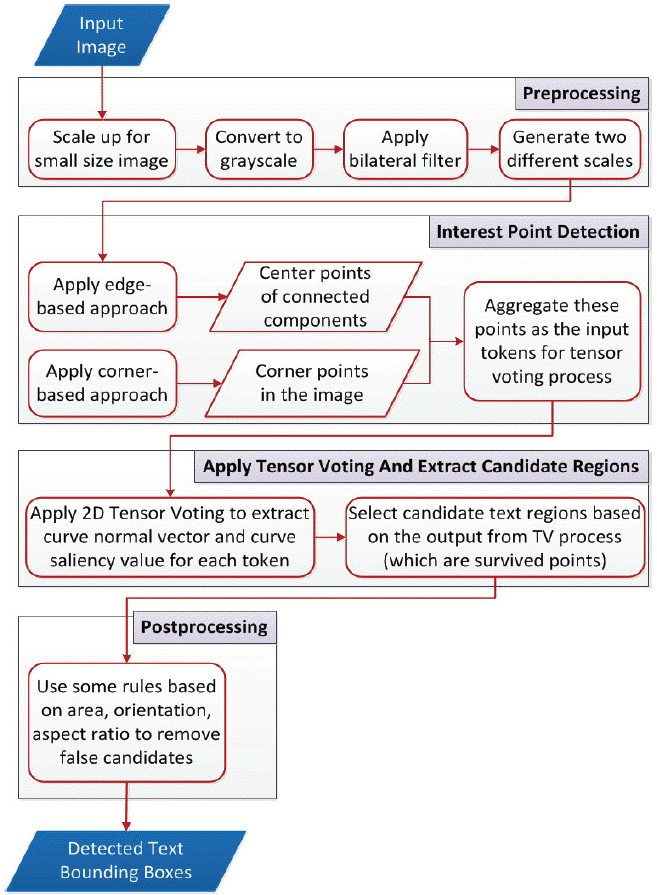
The proposed system has four stages: pre-processing, interest points detection, tensor voting to extract candidate text regions, and post-processing (Fig. 3). The input is a natural scene image and the output is the same image with red bounding boxes around the detected text regions. The input will be resized if it’s a small sized image. Then, it is converted to grayscale, filtered by a bilateral filtering technique [9], and duplicated into two images with different resolutions for the purpose of locating text in different sizes. In our implementation, both corner points detected by the Förstner-Köthe corner detector [10] and center points of connected components, which are obtained from a Sobel edge map, are aggregated together. These points are then encoded with 2D tensors and they are called tokens. Later, a tensor voting framework is applied to extract curve saliency values and normal vectors of these tokens. Finally, some rules are used to eliminate the rest of the non-text regions that are still remaining after previous phases.
2.2 Interest Point Detection
By ‘interest point’ we simply mean any point in the image for which the signal changes two- dimensionally. Conventional ‘corners’ such as L-corners, T-junctions, and Y-junctions satisfy this, but so do black dots on white backgrounds, the center of connected components, the endings of branches, and any location with a significant 2D texture [11]. In this paper we use the general term ‘interest point’ to indicate corner points and center points of edge connected components. Fig. 4 shows an example of general interest points detected on a sample image.
Many different interest point detectors have been proposed with a wide range of definitions for what points in an image are interesting. Some detectors find points of high local symmetry; others find areas of highly varying texture, while others locate corner points. Corner points are interesting as they are formed from two or more edges and edges usually define the boundary between two different objects or parts of the same object.
Förstner and Gülch [12] propose a two-step procedure for localizing interest points. The first points are detected by searching for optimal windows using the auto-correlation matrix A. This detection yields systematic localization errors (i.e., in the case of L-corners). A second step based on a differential edge intersection approach improves localization accuracy.
Köthe [12] improved the structure tensor computation using an increased resolution and non-linear averaging to optimize the localization accuracy. In our implementation, we applied a modified version of a Förstner corner detector that embraces some extensions proposed by Köthe.
To generate the binary edge map, the Sobel vertical edge-emphasizing method is applied to the grayscale image. The Sobel vertical edge magnitude is computed through the following convolution operation:
where, I is the grayscale image, E is the edge map, and S is the vertical Sobel kernel.
Edge connected components are defined as sets of connected edge pixels in the edge map. Center points of these connected components are then extracted.
2.3 Tensor Voting for Text Detection
In 2D tensor voting [14,15], each input token corresponds to a point or curve segment. Table 1 shows how input tokens are encoded as second order tensors. If the input token is a point, which does not have a preferential orientation, it is encoded with a ball tensor. Otherwise, it is encoded as a stick tensor with normal vector information.
Tensors support information including proximity and the smoothness of continuity by voting process. Tensors that lie on smooth salient features (i.e., curves) strongly support each other. Each tensor votes for its neighboring tensors with its information and also receives votes from them. The shape and size of this neighborhood and the voting strength and orientation are encapsulated in predefined voting fields or kernels. Each type of feature requires a voting filed. All voting fields can be generated from a fundamental stick voting field. For details of tensor voting, refer to [14,15].
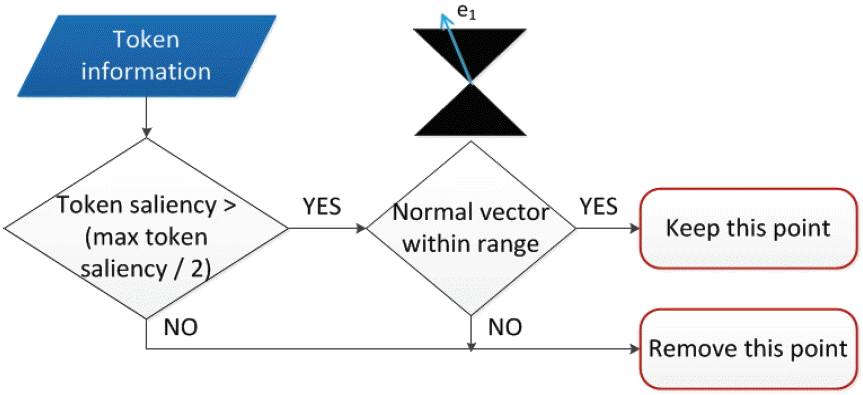
The positions of detected interest points are encoded with tensors and after that they are input to the 2D tensor voting framework. Tensors then propagate their information to their neighbors by voting algorithm. Since the distances between interest points are rather big, we set a large value for the scale of the voting field σ = 100. After tensor voting, the curve saliency value and normal vector of the token at each point are extracted. Fig. 5(c) visualizes these values with extracted interest points, in which the points, saliency values, and normal vectors of tokens are represented by the yellow dots, the lengths of the white lines, and the orientations of the while lines, respectively. It’s noticeable that in the text region, the tokens have high curve saliency values and their normal directions are likely the same as the normal vectors of text lines that they belong to. Therefore, we can use this information to remove more non-text regions.
The interest points corresponding to tokens that have small curve saliency values and nearly horizontal normal vectors, as described in Fig. 6, are removed. This step is presented in Fig. 5(d), which shows the remaining interest points after we remove others by using token information. The remaining interest points will be used to select the text regions.
2.4 Post-Processing
Rules used in the post-processing phase are based on area, orientation, and the aspect ratio of the input regions. These rules help to eliminate the rest of non-texts in various cases. They are constructed empirically by experiments and are described below.
2.4.1 Area
The area of a region is computed as the number of the foreground (or white) pixels in that region. We remove the regions, as shown in Fig. 7(d), with an area less than a threshold, which corresponds to noises in the test data
2.4.2 Aspect ratio
The aspect ratio of a bounding box is computed as its width over its height. Since texts are often positioned horizontally, a large enough aspect ratio value would be the sign of text than a small one would. We kept the regions with aspect ratios > 2, which comes from the observation that most of the bounding boxes for the text line have several characters aligned along the text line. Examples of removed regions are shown in Fig. 7(a) and (b).
2.4.3 Orientation
Orientation is defined as the angle (in degrees ranging from −90° to 90°) between the x-axis and the major axis of the ellipse that has the same second-moments as the region. Fig. 8 illustrates the axes and orientation of an input region. If the orientation is > 10° or < −10°, then it violates the assumption that the text lines are mostly horizontally aligned and the region will be removed.
3. Experimental Result
To evaluate the performance of the proposed method, we adopted the process in [8]. The input image set included 30 homemade wine label images captured by cellular-phone cameras and 80 images taken from the ICDAR 2003 Trial Test dataset [16]. The proposed method was implemented on a Windows XP system with Intel i5-2400 3.10 GHz and compared with the first implementation of a tensor voting-based method [8], edge-based method [6], and connected component (CC)-based method [7]. The comparison is carried out in terms of Precision and Recall, which are calculated by the following equations:
where, S is the total number of characters in images, T is the number of characters that are correctly detected, and F counts the number of regions incorrectly identified as texts. Table 2 shows some results from the proposed method. Table 3 summarizes the performance of the methods. The results show that the proposed method has better precision and recall than others. The tensor voting based method by [8] exhibits better performance than conventional edge-based [6] or CC-based [7] methods, while our method outperforms [8] because of the introduction of feature selection.
4. Conclusions
Since the first implementation of tensor voting in text detection, there have not been many improvements. It is true that by applying 2D tensor voting, the use of heuristic rules is minimized. Nevertheless, the tensor voting-based method failed to locate text in many cases and often generated various non-text regions in the result. To overcome these limitations, we proposed a novel method based on interest point detection. This method utilizes the fact that there is often a large amount of corner points of characters, and center points of connected components in text regions. The experimental results show that our method is effective in the detection of text in complex natural scene images.
For future work, we will consider using the curve saliency value and normal vectors to estimate the curvature of the text lines so that we utilize this information for text rectification.