Practical (Second) Preimage Attacks on the TCS_SHA-3 Family of Cryptographic Hash Functions
Article information
Abstract
TCS_SHA-3 is a family of four cryptographic hash functions that are covered by a United States patent (US 2009/0262925). The digest sizes are 224, 256, 384 and 512 bits. The hash functions use bijective functions in place of the standard compression functions. In this paper we describe first and second preimage attacks on the full hash functions. The second preimage attack requires negligible time and the first preimage attack requires O(236) time. In addition to these attacks, we also present a negligible time second preimage attack on a strengthened variant of the TCS_SHA-3. All the attacks have negligible memory requirements. To the best of our knowledge, there is no prior cryptanalysis of any member of the TCS_SHA-3 family in the literature.
1. Introduction
A hash function H takes an arbitrary length bit string M as input and outputs a fixed length bit string h (called hash value or digest). A cryptographic hash function is meant to satisfy certain security properties, the most important of which are listed below.
– First preimage resistance: given h, it is computationally infeasible to find an M such that H(M) = h.
– Second preimage resistance: given an M and H(M), it is computationally infeasible to find an M′ ≠ M such that H(M) = H(M′).
– Collision resistance: it is computationally infeasible to find an M and an M′, with M′ ≠ M, such that H(M) = H(M′).
The general model for cryptographic hash functions involves what is called a compression function. The function transforms a fixed-length bit string into a shorter, fixed-length bit string. The input message of a hash function, which is of arbitrary length, is partitioned into blocks of a fixed length (called the block length). However, before this can be done, it is required that the length of the message is a multiple of the block length. Given this and some security considerations, the message is ‘padded’ with bits in one of several ways (some padding schemes can be found in [1]). The message blocks are sequentially processed, with the compression function acting on the message blocks until all the blocks are processed. The end result is output as the digest. The general model for describing hash functions can be found in greater detail in [1].
A cryptographic hash function family is proposed by Vijayarangan of the Tata Consultancy Services (hereinafter called ‘TCS’) in [2]. The family is comprised of four hash functions, as four digest sizes (224, 256, 384, and 512 bits) are allowed. In [2], the hash functions are all actually called SHA-3, except in one or a few instances (see e.g., Clause 0095 of [2], where a member hash function is called TCS_SHA-3). However, as the name SHA-3 (with ‘SHA’ standing for ‘Secure Hash Algorithm’) has been in use by the National Institute of Standards and Technology (NIST), USA [3], we use the less common ‘TCS_SHA-3’ to denote the SHA-3 of [2]. Further, we denote by TCS_SHA-3-d the member that produces d-bit digests.
The design of TCS_SHA-3 deviates from the general model in that the compression function is replaced by a bijective function. This function uses a linear feedback shift register (LFSR) and a T-function. The design goals, as stated in [2], are to ‘prevent hash collisions’ and to ‘provide a secure hash function.’ This paper establishes that the design goals have not been met.
Motivation behind this work
The TCS, headquartered in India, is one of the largest IT services providers in the world, with annual revenue of more than $10 billion for 2011–2012 [4]. In May 2012, the company was named the fourth most valuable IT services brand worldwide, based on image, reputation and intellectual property assessments [5]. The company’s annual research report for 2007–2008 mentions the following [6]:
“In the current year, major work has been done on cryptographic algorithms and hash functions, which form the basis of all data security today. Past research products [from the E-Security group of the TCS Innovation Labs, Hyderabad, India,]… are in active use around the country (India) by various customers in the banking and financial services industry. Organizations using our technology, directly or indirectly, include the RBI [(Reserve Bank of India)], National Securities Depositories [sic] Limited (NSDL), Ministry of Company [sic] Affairs (MCA), and many public sector banks.”
Since TCS_SHA-3 is a product of the above-mentioned E-Security group of the TCS Innovation Labs [6], there appears to be sufficient motivation to evaluate the security of the hash function family.
Contributions of this paper
This paper makes three contributions. First, we report a second preimage attack that requires negligible time and negligible memory for nearly guaranteed success. Second, we describe a first preimage attack on the TCS_SHA-3-d that requires O(227 · d) time and negligible memory. Third, we present a second preimage attack, which also requires negligible time and negligible memory for nearly guaranteed success, on a strengthened variant of the TCS_SHA-3.
To the best of our knowledge, there is no prior published attack on the (strengthened) TCS_ SHA-3.
Organization of this paper
Section 2 describes the TCS_SHA-3 family of hash functions. A second preimage attack and the first preimage attack are respectively described in Sections 3 and 4. In Section 5, we present the second preimage attack on the strengthened TCS_SHA-3. We conclude in Section 6. Appendix A provides the results of our simulations of the first preimage attack.
2. Specifications
We will first list the notation and conventions, which are used in the rest of this paper, in Table 1.

Notation and conventions
The TCS_SHA-3-d takes a message M of arbitrary length as input and returns a digest h (also denoted TCS_SHA-3-d(M)) of size d bits after the following sequence of processes, which include six ‘rounds.’
-
Padding: The input M is partitioned into k = ⌈|M|/d⌉ blocks (denoted M1, …, Mk), where each is d bits in length. Clause 0068 of [2] states that an initialization vector (IV) of length d is added to a message if and only if the size of the message is less than d. The designer should have evidently mean the following: if and only if |Mk| < d, for any k ≥ 1, then Mk is added with the IV. Otherwise, the TCS_SHA-3 can only be applied to single block messages or multiple block messages, in which each one satisfies the condition d | |M|. For the simulations of Appendix A, we made the assignments IV = 12 || {02}d–1, d = 224, 256, 384, 512. The assignments are motivated by a case provided in [2] where the IV is chosen to be 12 || {02}223 when the size of the message is less than 224 bits. In our simulations, as well as in the aforesaid example case, the IV is XORed with the corresponding message block. In summary, the padding rule is defined as follows: for any k ≥ 1,
(1)An implicit assumption in the above discussion is that |Mk| is nonzero. Furthermore, when |Mk| = d, we infer that there is no extra ‘padding block’ that is appended to M. This is because, in such a case, there is no message block to which the IV (= 12 || {02}d–1) could be ‘added’.
-
Round 1: The first round has k steps; the steps are as follows:
-
Step 1 when k > 1: An arbitrarily chosen d′-bit (such that d′ ≤ d) constant c is XORed with M1. The output, c ⊕ M1, is input to a bijective function F (defined later in this section). Thus, a d-bit string, F(c ⊕ M1), is output.
Step 1 when k = 1: The arbitrarily chosen constant c is XORed with
-
Steps 2 to k (i.e., when k ≥ 2): Step i, 2 ≤ i ≤ k – 1, is given by the following recursion:
(2)Step k is given by:
(3)where
-
-
Round 2: Like round 1, round 2 also proceeds iteratively. The number of steps, s, is such that k “is not always the same as” s (see [2]). The input to round 2 is
Step 1: The d′-bit constant c is XORed with
-
Steps 2 to s (i.e., when s ≥ 2): Step i, 2 ≤ i ≤ s, is given by the recursion:
(4)
-
Rounds 3 to 6: These rounds are similar to round 2. The number of steps in each of these rounds is, again, s. The input to round j, 3 ≤ j ≤ 6, is
Step 1: Constant c is XORed with
-
Steps 2 to s (i.e., when s ≥ 2):1 Step i, 2 ≤ i ≤ s, is given by the recursion:
(5)
The d-bit digest h is simply the final output,

The working of TCS_SHA-3 (k ≥ 2) works.

The bijective function F:{02, 12}d → {02, 12}d
3. Second Preimage Attack on TCS_SHA-3
Let
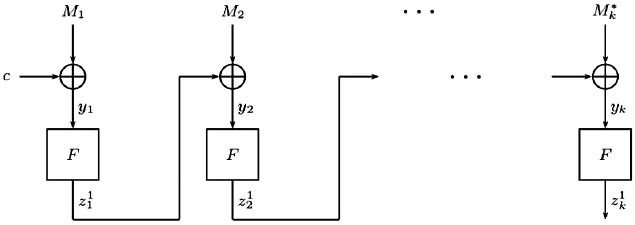
Round 1 of TCS_SHA-3.
It is straightforward to see that the conditions:
satisfy (6) and when
4. First Preimage Attack on TCS_SHA-3
Fig. 3 illustrates Algorithm 1 for the (sample) case when d = 256.

The bijective function F of TCS_SHA-3-256; S, T and L are 32-bit to 32-bit functions.
From Fig. 3, we see that the TCS_SHA-3-256 (and the TCS_SHA-3 per se) has poor diffusion properties. A difference in αi, for any i ∈ {1, 2, …, d/32}, affects λi alone. A single-bit difference in αi, for any i ∈ {1, 2, …, d/32}, is ideally expected to affect 16 bits of λi.
Let us consider the case when k = 1. Then, given an input difference
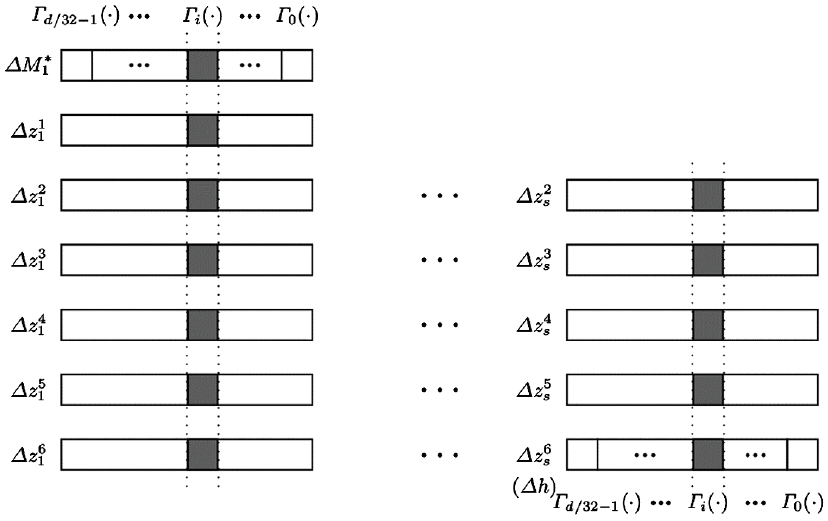
Differential characteristic for TCS_SHA-3-d when k = 1; non-zero differences are confined to the grey boxes.

Recovering M1 from h when k = 1
Algorithm 2 requires that the attacker knows whether |M1| = d or |M1| < d. However, even without this information the attacker can, at the very least, recover all but the most significant bit of M1 by simply computing
As we can see, Algorithm 2 has d/32 · 232 = d · 227 iterations. Since d ≤ 512, single block messages can be recovered from their respective hash values in O (512 · 227) = O (236) time. Therefore, it may be extremely risky to use the TCS_SHA-3 for something like password hashing (a well-known application of cryptographic hash functions, see [9]).
For the case when k > 1, if the message blocks M1, …, Mk–1 are available to the attacker, then Mk may be recovered. The attack procedure is now given by Algorithm 2 with M1 replaced by Mk and
5. Cipher Block Chaining in Algorithm 1: Impact on Security
In Algorithm 1, the 32-bit words α1, α2, …, αd/32 are processed independently of one another (see Fig. 3). This is an inference that we draw from [2], which does not explicitly mention there being any dependence between the processing of αi and the processing of αi+1, 1 ≤ i ≤ d/32 − 1. Furthermore, [2] provides several implementation results, but the corresponding implementation is missing. We were therefore unable to verify the correctness of the implementation results of [2]. If the implementation results are correct, then the processing of αi and the processing of αi+1, 1 ≤ i ≤ d/32 − 1, may not be independent (see e.g., [2]). However, even in such a case, the existence of dependence must have been clearly mentioned in [2] in any of the clauses preceding Clause 0087.
When there is dependence in the form of chaining, given the structural similarities between TCS_SHA-3 and Khichidi-1 (see [7]), it appears reasonable to expect the chaining mechanisms in the two cases to be identical. From [7] then, we see that Fig. 2 changes to Fig. 5 when k = 2.5,,6, Clearly this would also mean that FIGURE 3 of [2] is incorrect.

Round 1 of TCS_SHA-3 (k = 2) with 32-bit cipher block chaining; α1, j = Γd/32–j (M1) and
Note: If one goes by [7], then in Fig. 5,
However, the case of the aforementioned independent processing of the 32-bit blocks complies with FIGURE 3 of [2] and thus enhances our belief in the correctness of the above-mentioned inference of independent processing of the αi′s (1 ≤ i ≤ d/32). Yet we shall now examine the impact of cipher block chaining in Algorithm 1.
Let
Suppose that the conditions
It is straightforward to see that the conditions:
satisfy (10) and when α′1, d/32 ≠ α1, d/32, we have a second preimage. Under reasonable assumptions of uniformity, the event α′1, d/32 = α1, d/32 occurs with negligible probability.
6. Conclusions and Open Problems
In this paper, we have presented what we see as being the first practical (second) preimage attacks on the TCS_SHA-3 family of patented cryptographic hash functions. The second preimage attack requires negligible time and negligible memory for nearly guaranteed success. The attack works when the number of message blocks is at least two. The first preimage attack requires O(236) time and negligible memory. This attack is most efficient (going by data requirements) on single block messages -- negligible data is required in such cases. We have also reported a negligible time/memory second preimage attack on the TCS_SHA-3 that is strengthened with 32-bit cipher block chaining. This attack also works only when the number of message blocks is at least two.
Our findings establish, amongst other things, that the TCS_SHA-3 may be particularly unsuitable for password hashing (unless, for example, it is strengthened with 32-bit cipher block chaining).
It may be an interesting exercise to find countermeasures to our attacks.
Notes
Perhaps the only criterion that s must satisfy is s > 1; otherwise, the TCS_SHA-3-d will have only one round.
The (second) preimage attacks that we report in this paper are independent of the value of s, which is due to reasons that would be understood from Sections 3 and 4.
We omit the full description of the LFSR as it is elaborate and not relevant to our analysis (to be understood from Sections 3 and 4). In [2], the LFSR is described in Clauses 0078-0083.
A similar correcting block attack on the hash function Khichidi-1 [7] has been reported by Mouha [8].
The bijective function g: {02, 12}32 → {02, 12}32 of Fig. 5 is given by Algorithm 3.

The bijective function g:{02, 12}32 → {02, 12}32
References
Appendices
Appendix A Experiments
We took a few sample outputs of TCS_SHA-3 and attempted to verify their first preimages. Simulations were performed on a NVIDIA GeForce GT 540M graphics processing unit (GPU) having 96 CUDA cores (2 multiprocessors × 48 CUDA cores / multiprocessor) and a clock rate of 1.34 GHz. The CUDA C compiler nvcc 4.2 was used. Below is a list of assignments made for the simulations and their justifications (see also footnotes 1,–3 and Section 4).
– See footnote 6. As the value of c has no bearing on the analysis or the experiments, we assign the value {02}d to c.
– The IV is 12 || {02}d–1 (see Section 2).
– The value of s is taken to be the value of s in Khichidi-1 (see [7] and khichidi.c in the URL provided in [10]), and is therefore equal to 2.
– The value of ηi is 1 for all i ∈ {1, 2, …, 6}; the number of LFSR shifts in round i of Khichidi-1 is also 1 for all i ∈ {1, 2, …, 6} (see [7] and khichidi.c in the URL provided in [10]).
The system time taken to find the first preimage for each output, given the above set of assignments, is provided in Table 2. These system times are expected to remain unaltered when a different IV or c is used.

First preimage samples
As shown in Sections 2 and 4, it follows that the time/memory complexity of our first preimage attack does not change when one or more of the above-listed assignments are altered.
Biography
Gautham Sekar

He received his bachelor’s degree in Electronics and Instrumentation Engineering from the Birla Institute of Technology and Science, Pilani, in June 2006. He simultaneously graduated with a master’s degree in Physics from the same institute. In November 2006, he joined the COSIC (Computer Security and Industrial Cryptography) group of the Katholieke Universiteit Leuven, Belgium, as a pre-doctoral student and from October 2007 to March 2011 he worked there as a doctoral student under the supervision of Prof. Dr. Bart Preneel. Upon obtaining his Ph.D., he worked at the National University of Singapore as a Research Scientist until March 2012. Since then, he is a Visiting Assistant Professor at the Indian Statistical Institute, Chennai Centre. In May 2007, he received the Dr. Ranjit Singh Chauhan Undergraduate Research Award from the Birla Institute of Technology and Science, Pilani. His research interests include cryptography, cryptanalysis, and information security in general.
Soumyadeep Bhattacharya http://orcid.org/0000-0002-9386-7513

He received his bachelor’s degree in Electrical and Electronics Engineering and master’s degree in Physics from the Birla Institute of Technology and Science, Pilani, in June 2010. He is currently a Senior Research Fellow in Theoretical Physics at The Institute of Mathematical Sciences, Chennai. His research interests are statistical physics and parallel computing.