1. Introduction
Face recognition has been one of the main research problems in the pattern recognition area. The traditional face recognition problem is to assign a label (or name) to the given face image and it has many applications, such as security, login and authentication.
Recently, the Labeled Faces in the Wild (LFW) database [1] has been issued for studying the problem of unconstrained face recognition and it has become the de facto standard test set for face recognition and verification. Since the issuing of the LFW database, most face recognition researchers have focused on studying the face verification problem, which is to determine whether or not a given pair of facial images belongs to the same subject. This problem has many practical applications, such as the case that only one sample per class is available for training.
Most face verification methods have two phases: feature extraction and (same/not-same) binary classification. The feature extraction methods can be categorized into the hand-crafted and learning-based methods. A typical handcrafted feature can be a concatenated histogram by using LBP [2] or LE [3] in the grid type cell [2,4] or at the facial landmark points [5], while a learning-based feature extraction method typically utilizes the deep neural networks (DNNs) [6–8]. For binary classification, the Joint Bayesian (JB) method was introduced for this kind of pair test in 2012. Since then, the JB method has served as the classification part in many state-of-the-art face verification methods. According to the LFW results in the unrestricted protocol, the JB method is used as a classifier in most top face verification algorithms, including DeepID2+ [9], which is the best so far.
The JB method proved most promising, but it has not been improved since 2012 and the original version of the JB method is still being used. The only improved version of the JB method is the transfer learning JB method [10]. But it can be applied only when the source and target domains are different. In the end, the original JB algorithm has not been improved so far.
In this paper, we propose an improved version of the JB method, a so-called two-dimensional Joint Bayesian method. It is very simple and efficient in both training and test phases. The main idea of the proposed method is to separate two symmetric terms from the three terms of the JB log likelihood ratio. Then, a decision line is learned in the two-dimensional Euclidean Space to separate same and not-same cases (refer to Section 3.2). This kind of idea can apply to many decision-making problems whose decision functions have more than one term. The coefficients of the terms can be replaced by some unknown constants and be learned from training data.
In Section 2 we review the related work with the face verification methods using the JB method. Section 3 describes the proposed two-dimensional JB method as well as providing a detailed explanation of the original JB method. The experimental results are given in Section 4 and we present our conclusions in Section 5.
2. Related Work
In this section we will review the face verification methods that use the JB method and test on the LFW database. This paper describes face pair-matching methods developed and tested on the LFW benchmark. The LFW dataset was published with a specific benchmark, which focuses on the face recognition task of pair matching (also referred to as “face verification”). As a benchmark for comparison, researchers reported performance as 10-fold cross validation using splits in the view2 file. The LFW database contains 13,233 face images of 5,749 identities collected from the Web. In LFW, there are a total of 5,749 subjects, but only 95 individuals have more than 15 images. For 4,069 people, just one image is available.
To improve the performance, many state-of-the-art face verification methods took supervised approaches using very big outside training datasets, which contain sufficient intra-personal and extra-personal variations. For example, DeepFace [11] was trained using around 7,400,000 face images from Facebook and achieved 97.25% verification accuracy in LFW.
The JB [4], High-dim LBP [5], and TL Joint Bayesian [10] algorithms are trained on the WDRef (Wide and Deep Reference) dataset and achieved 92.42%, 95.17%, and 96.33%, respectively. WDRef contains 99,773 face images of 3,000 subjects, where around 2,000 subjects have more than 15 images and around 1,000 subjects have more than 40 images. DeepID [6] and DeepID2 [7] algorithms are trained on the CelebFaces+ dataset and achieved 97.45% and 99.15%, respectively. CelebFaces+ contains 202,599 face images of 10,177 celebrities.
In training the DeepID2+[9] algorithm, the training data is enlarged by merging the CelebFaces+ dataset [6], the WDRef dataset [4], and some newly collected identities exclusive from LFW. The DeepID2+ net is trained with around 290,000 face images from 12,000 identities, as compared to the 160,000 images from 8,000 identities used to train the DeepID2 net.
From the experimental results of all these methods, the performance increases almost linearly or in log scale as the size of training data increases. For example, the JB and DeepID2 results shows that they need about 1.25 and 40 times the amount of training data, respectively, to increase their performance by 1% on average. In this paper, our experimental results will show that the proposed 2D-JB method can increase the performance by more than 1% without increasing the size of the training data.
3. Two-Dimensional Joint Bayesian
In this section we describe the proposed two-dimensional Joint Bayesian method. First, we review the original JB method and then we explain our main idea.
3.1 Original Joint Bayesian Method
In this section we explain the JB method [4] in detail. We represent a face image as a (feature) vector. Let the vector be a random variable x. Then, a face is assumed to be represented by the sum of two independent Gaussian random variables as follows:
where ε represents facial variations (e.g., light, pose, etc.) and μ represents the face mean of the identity.
We assume that the mean of x is 0 (this is possible if we subtract the mean of all faces from x). Then we have:
where Sμ and Sɛ are unknown covariance matrixes. From Eq. (1), we have:
We consider joint distribution of {x1, x2}. Then we have:
From expression (3) and the fact that μ and ɛ are independent, we have:
Depending on whether x1 and x2 are the same person (HI) or different persons (HE), the corresponding covariance matrices are different. First, assume that they are the same person. Under the assumption HI, we have μ1 =μ2, and ɛ1 and ɛ2 are independent. Therefore, the covariance matrix of P(x1,x2|HI) is given by:
Now, we consider x1 and x2 to be different individuals. Under the assumption HE, μ1 and μ2 are independent, and ɛ1 and ɛ2 are independent. The covariance matrix of P(x1,x2|HE) is given by:
We define similarity value of x1 and x2 by:
Then, by the definition of multivariate normal distribution, we have:
Since the second term
1 2 log ( ∣ Σ I ∣ ∣ Σ E ∣ ) Σ E - 1
From the structure of ∑I, we can assume that:
The matrices F and G can be determined by calculating the inverse matrix. Let A = (Sμ + Sε)−1 – (F + G). Then, by omitting the second term of Eq. (9), we have:
Since G is symmetric, by omitting a constant 1/2, we finally have the JB similarity equation:
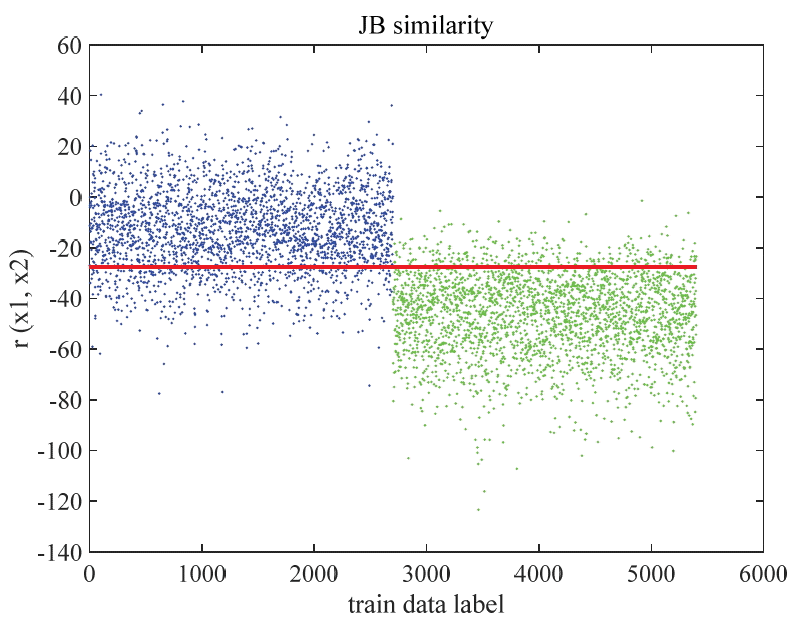
In Fig. 1, we give an example of r(x1,x2). The first 2,700 training data labels are the same person pairs (HI, blue), and the second 2,700 training data labels are not same person pairs (HE, green). The horizontal line (red) is the decision line (threshold value). In this figure, the threshold value is −27.63 and the training accuracy is 86.09%. We applied this threshold to the test data for same and not-same binary classification.
3.2 Two-Dimensional Joint Bayesian Method
In the previous section, we looked at the original JB method. We will now explain how we developed the JB method and consider the two-dimensional Joint Bayesian (2D-JB) method. For the given two face features x1 and x2, the original JB method uses the similarity measure shown in (13) and a threshold value for decision. For 2D-JB, we propose two features as follows:
These X1 and X2 are parts of the similarity measurement in (13). With these two feature values, we propose the following decision function:
To learn the parameters θ=(θ0, θ1, θ2) from data, we can use the logistic regression (LR) [12] or a support vector machine (SVM) [13] so that our decision rule is that if r2D(x1,x2)>0, x1 and x2 are the same, otherwise, x1 and x2 are not the same.
The proposed 2D-JB has a decision line, while the original JB is a decision scalar value. The proposed 2D-JB can be considered as an extension of the original JB since its decision function r2D(x1,x2) is reduced to r(x1,x2) when θ1 =θ2 =1 and θ0 is the negative value of the threshold of the original JB method.
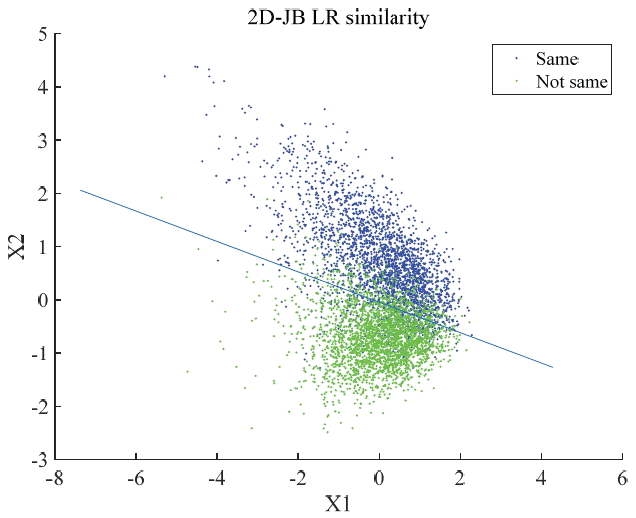
In Fig. 2, X1 and X2 values are represented by points (X1,X2) in R2. The blue points correspond to the 2,700 same person pairs and the green points correspond to the 2,700 not-same person pairs. The straight line (blue) in Fig. 2 is the decision line, which is determined by the logistic regression of 1 degree. The equation of the decision line is θTX=0, where θT = (0.17,1.11,3.88) and X= (1,X1,X2). The training accuracy is 86.98%.
4. Results
In this section, we compare the original JB and the proposed 2D-JB methods. The dataset that we used is the Label Face in the Wild-a (LFW-a) [1]. It contains 13,233 face images that are the same as the original LFW dataset, but the images were aligned using commercial face alignment software. In this section, we present two experimental results using global and local LBP features.
4.1 Face Verification Using Global LBP Features
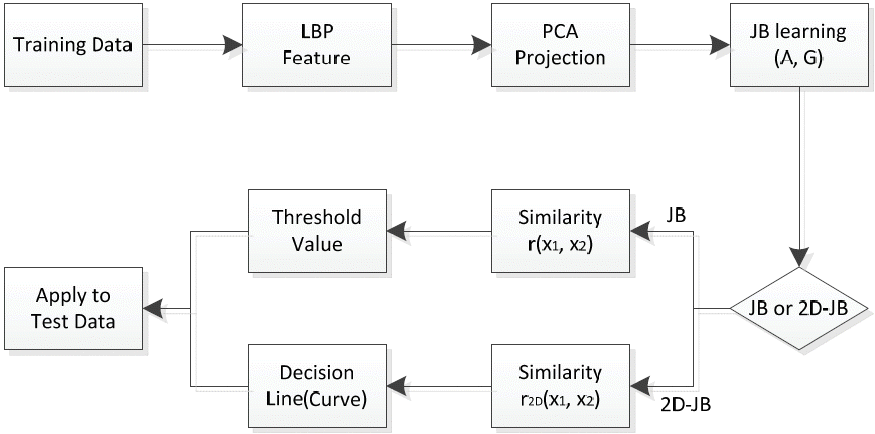
Fig. 3 shows the evaluation procedure in our experiments that we used to compare the JB and 2D-JB methods. For training, we used two types of data. The first training data is the minimal data in LFW DB, which we can use when we follow the LFW protocol. We call it the View2 data. There are ten folds in LFW View2 data pairs. For each fold, we used all of the images that belong to the identities of the remaining nine folds. For the second training data, we used all of the LFW data that does not belong to the test fold. We call this the Augmented View2 data. In all of our experiments, we used images that were flipped horizontally and original images for training. To obtain the normalized face regions, we cropped the 80×120 regions in the middle of the images of LFW-a.
We used two types of local binary pattern (LBP) feature extraction methods:
L B P 8 , 1 u 2 L B P 8 , 1 u 2 ; L B P 8 , 2 u 2 L B P 8 , 1 u 2 L B P 8 , 2 u 2 L B P 8 , 1 u 2 ; L B P 8 , 2 u 2 L B P 8 , 1 u 2 L B P 8 , 2 u 2 L B P 8 , 1 u 2
Fig. 4 shows the mask indicating where the LBP histograms were extracted. Every cell is 10×10 in size and we did not extract the LBP histograms in the black cells. Therefore, the feature dimension is 4,720 (= (12×8–16) ×59) for
L B P 8 , 1 u 2 L B P 8 , 1 u 2 ; L B P 8 , 2 u 2
We applied the Principal Component Analysis (PCA) to reduce the feature dimensions. To obtain the PCA axes we use the flipped data and original data. In our experiments, the PCA dimension varies from 100 to 900. It is worth noting that the PCA dimension reduction boosts the verification performance.
The matrices A and G in JB training, which is described in Section 3.1, are obtained using the subjects whose number of images in LFW DB is greater than or equal to a predefined number. In our experiments, the predefined number varied from 3 to 9. When we determined the decision boundaries for 2D-JB, we applied LR and a SVM for performance comparison. In LR, we used the polynomial LR of 1 and 2 degrees, while we used the linear and Gaussian kernels in SVM.
The results of our experiments are summarized in Tables 1 and 2 where Table 1 is for View2 training data and Table 2 is for Augmented View2 training data. As shown in Tables 1 and 2, our 2D-JB method is better than the JB method by about 1%. The best test accuracy was 88.70% (shown in Table 2) using the 2D-JB-LR of 2 degrees and 2D-JB-Gaussian SVM.
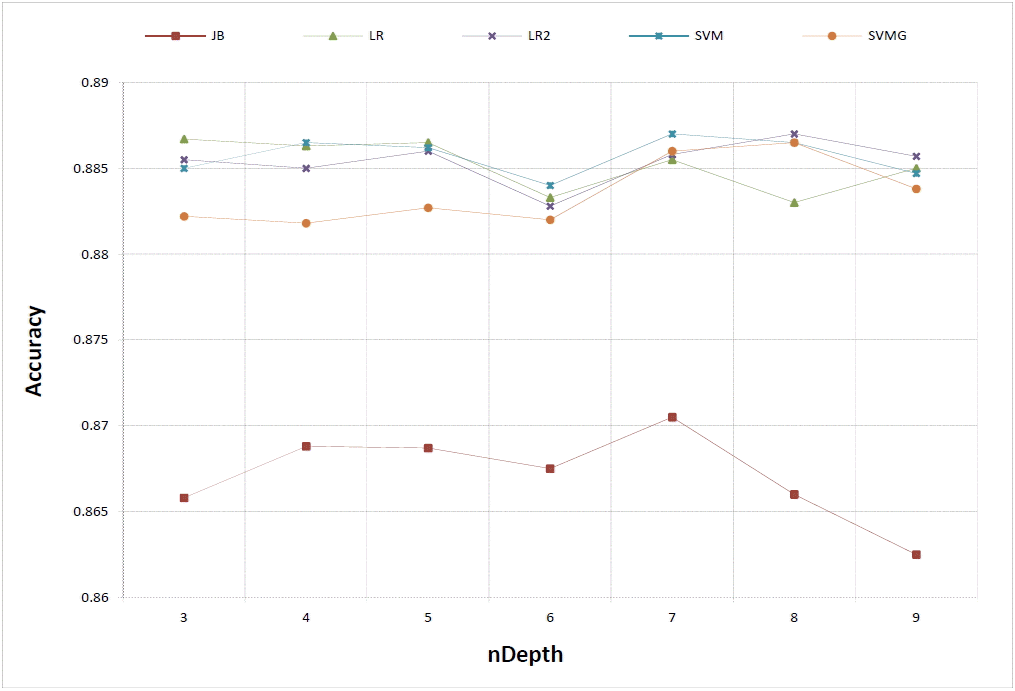
We investigated the effect of the PCA dimension and the depth [4] of training data on the performance in detail. By depth of training data, say nDepth, we mean the minimum number of images of each subject to be trained. For example, when we say nDepth = 3, we estimate the matrix A and G of the JB method using the images of the subject having more than two images in the LFW database.
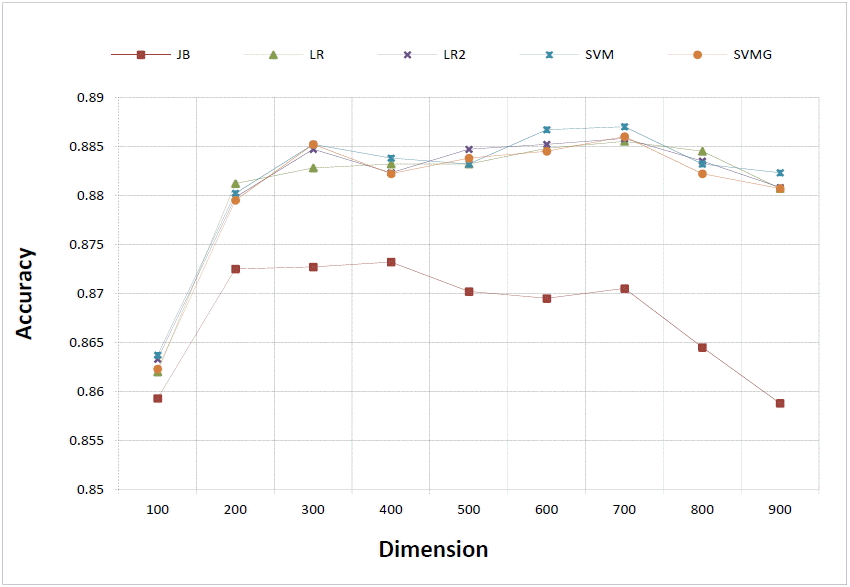
In Fig. 5, we show the changes in accuracy as the PCA dimension varies, where we used the [
L B P 8 , 1 u 2 ; L B P 8 , 2 u 2
Fig. 6 shows the accuracy change according to nDepth using the [
L B P 8 , 1 u 2 ; L B P 8 , 2 u 2
4.2 Face Verification Using Combined Local and Global LBP Features
The feature extraction methods in Section 4.1 are global in that they extract the LBP histograms in the equally divided 10×10 cells in the image. They cannot compare the corresponding facial component due to pose and expression. This remains true even if the face images are normalized by similarity transformation based on their landmark points. Chen et al. [5] showed that feature sampling at the landmarks effectively reduces the intra-personal geometric variations due to pose and expressions.
In this experiment, we extracted the [
L B P 8 , 1 u 2 ; L B P 8 , 2 u 2 L B P 8 , 1 u 2 ; L B P 8 , 2 u 2
Table 3 shows the JB test results according to the PCA dimension and nDepth. The best result in each PCA dimension is indicated in bold. Table 3 shows that the 2D-JB method always outperforms the original JB method in every case.
We performed the paired t-test using the accuracy data in Table 3. For the null hypothesis of μ1 =μ2, the p-value is 3.93×10−15, which proves that the proposed 2D-JB method significantly outperforms the original JB method from a statistical point of view.
5. Conclusion
Since the publication of the original JB method, it has been used in most state-of-the-art face verification methods, but there hasn’t been an improved version of it published so far.
In this paper, we proposed an improved Joint Bayesian (JB) method for the face verification task. We call it two-dimensional Joint Bayesian (2D-JB) method. It is very simple and efficient in both training and test phases. The main idea of the proposed method is to separate two symmetric terms from the three terms of the JB log likelihood ratio. Then, a decision line is learned in a 2D Euclidean space to separate same and not-same cases. We used LR and a SVM to learn the decision line.
We conducted numerous experiments, beyond the ones we have mentioned here, with the JB and 2D-JB methods. It was very rare that the original JB method outperformed the 2D-JB method. In most cases, the 2D-JB method outperformed the JB method by 1%–3%. Referring to [4,6,7], many state-of-the-art verification methods need tons of training data to improve their accuracy by 1% in the LFW database. However, the 2D-JB method can do so in a simple manner.